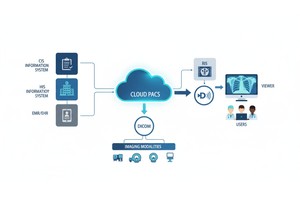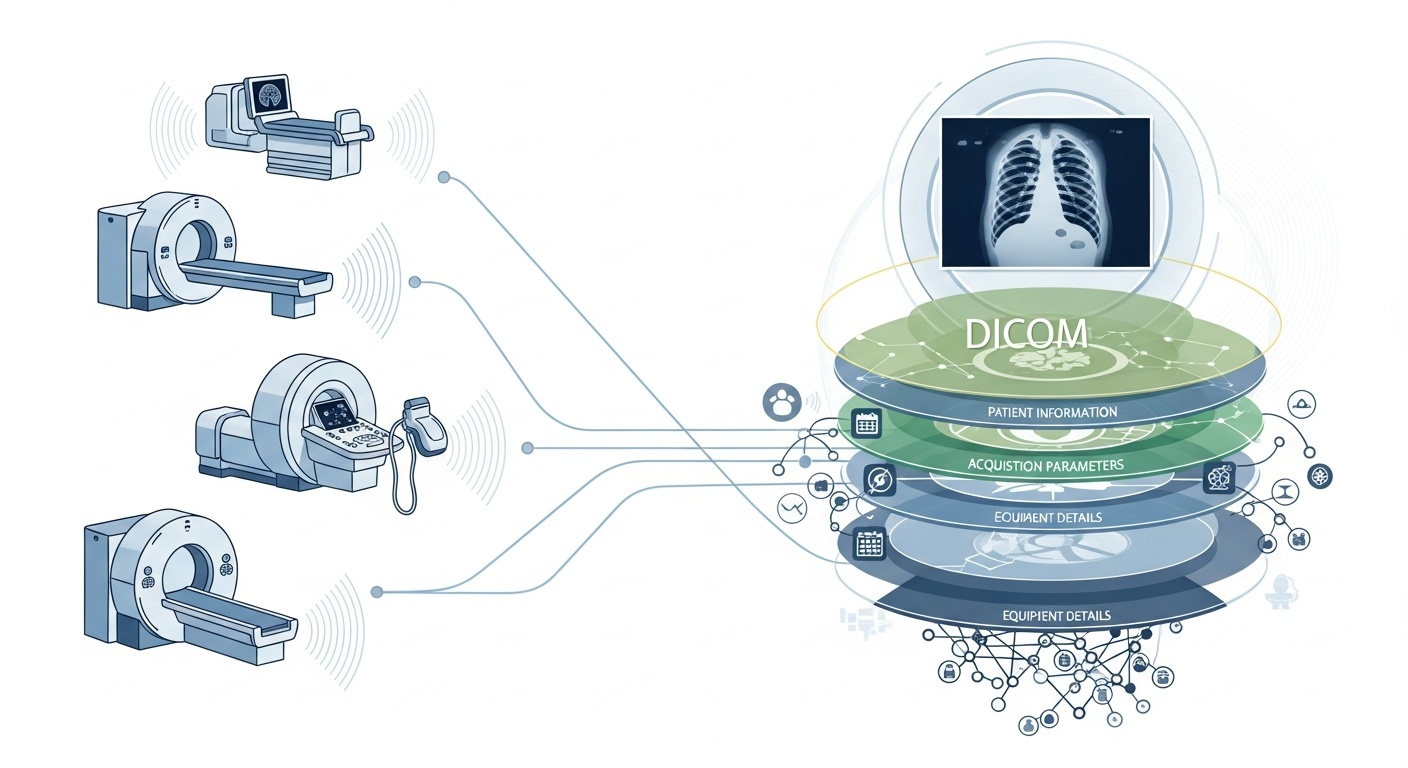
Hver gang et radiologiteam scanner en patient, f.eks. en CT, MR eller ultralyd, genereres en kaskade af data. Mest synligt er selve billedet, men bag det ligger et rigt lag af metadata: hvem, hvad, hvornår, hvordan og hvor for scanningen. Dette lag styres af standarden DICOM (Digital Imaging and Communications in Medicine), en standard for medicinsk billedformat, der blev fastlagt af National Electrical Manufacturers Association (NEMA) og American College of Radiology (ACR) for årtier siden.
Det, der gør metadata så interessante, er, at de er strukturerede, maskinlæsbare og bemærkelsesværdigt detaljerede: udstyrsindstillinger, optagelsesparametre, patientdemografi, undersøgelses-ID'er, endda institutionskoder og producentoplysninger for modaliteten. Denne rigdom muliggør big data-analyse, downstream-forskning, AI-modellering og protokolstandardisering, hvis du udnytter den rigtigt.
I forbindelse med big data taler vi ikke kun om et par dusin billeddiagnostiske undersøgelser. Vi taler om hundreder af tusinder eller endda millioner af billeder på tværs af modaliteter, steder og leverandører, med metadata som det vigtigste indekslag: "hvem & hvornår & hvordan" for hvert element. Uden effektiv udnyttelse af metadata risikerer du at have et massivt arkiv af billeder men minimal evne til at søge, sammenligne eller udlede indsigt fra dem. En nylig gennemgang fastslår: "størstedelen af information, der er lagret i PACS-arkiver, tilgås aldrig igen," hvilket er en spildt mulighed.
Forestil dig, at du kører et studie på tværs af flere steder med lunge-CT-scanninger til tidlig påvisning af emfysem. Du vil vælge scanninger baseret på parametre: scannerleverandør/mærke/model, snittykkelse, rekonstruktionskerne, patientalder, datointervaller, måske endda dosisparametre. De fleste af disse er metadatafelter, ikke pixeldata. Ved at udtrække disse tags kan du opbygge kohorten, ekskludere inkompatible scanninger (f.eks. for tykke snit) og sikre sammenlignelighed.
Metadata giver dig mulighed for at overvåge selve billeddannelsesprocessen: bruger institutionen den korrekte protokol? Afviger optagelsesparametrene over tid (f.eks. synsfelt, timing af kontrastinjektion)? Er leverandørindstillingerne konsekvente? I en big data-verden, hvor tusindvis af scanninger finder sted dagligt, kan du ikke stole på manuel gennemgang. Du har brug for analyse af metadata. Mange PACS-systemer underudnytter metadata af denne årsag.
Hvis du bygger en AI- eller radiomics-pipeline, kan du ikke behandle hvert billede som værende udskifteligt. Metadata bliver en integreret kontrolvariabel: inputfunktioner inkluderer ofte modalitet, kVp (kilovoltage peak), producent, kerne, snittykkelse, og selv dato eller hospital kan have betydning (domæneskift). Disse metadatafelter hjælper med at styre bias, harmonisere data og annotere billeder med kontekst. Mange forskere kalder metadata "lige så vigtige som pixeldata."
Big data betyder skala. Det indebærer varierede kilder, flere leverandører, forskellige institutioner og heterogene formater. DICOM-metadata er det standardiserede "sprog", der hjælper med at forene metadatalaget, muliggøre søgning/indeksering, sikre interoperabilitet og opbygge skalerbare arkitekturer (Cloud PACS, fødererede arkiver). Men implementeringen betyder noget. Det samme PMC-studie fandt, at mange systemer ikke udnytter standarden fuldt ud.
PostDICOM tilbyder et cloud-baseret PACS (Picture Archiving and Communication System) til lagring, visning og deling af billeddiagnostiske undersøgelser og kliniske dokumenter. Nogle centrale metadata-relevante funktioner i PostDICOM:
• Understøttelse af DICOM-tags & beskrivelser: Vores ressourcebibliotek viser "DICOM-modalitet & tags", hvilket giver brugere adgang til tag-lister og beskrivelser.DICOM-modalitet & tags
• API / FHIR-integration: Det understøtter API- og FHIR-grænseflader (Fast Healthcare Interoperability Resources), hvilket gør det muligt at forespørge metadata programmatisk, integrere med andre systemer og analysere dem.
• Cloud-skalerbarhed & deling på tværs af steder: Deling på tværs af patienter, læger, institutioner; ubegrænset skalerbarhed betyder, at big data-pipelines bliver mulige.
• Avanceret billedbehandling & multimodalitets-understøttelse: Selvom dette vedrører pixels, betyder understøttelsen af modaliteter som PET–CT og multi-serier, at metadata er betydelige (SUV-værdier, fusionsvolumener, modalitetstype) og tilgængelige for analyse.
Ved at bruge en platform som PostDICOM kan du udnytte metadata gennem strukturerede workflows, API'er og cloud-arkitektur.
Sådan struktureres workflowet fra rå arkiver til analyse-klar indsigt.
 - Created by PostDICOM.jpg)
Det første trin i at udnytte DICOM-metadata til analyse er udtræk og normalisering. Biblioteker såsom open-source Python-pakken PyDicom bruges almindeligvis til at parse DICOM-filer og udtrække relevante tags, herunder billedrækker og -kolonner, konvolutionskerner og modalitetsspecifikke optagelsesparametre.
Håndtering af heterogenitet er afgørende, da forskellige leverandører ofte bruger private tags eller ikke-standardiserede implementeringer. Robust parsing, fallback-logik og omfattende tag-mapping-tabeller er nødvendige for at sikre konsistens på tværs af datasæt.
Når de er udtrukket, skal metadata normaliseres og mappes til standardontologier og strukturer, såsom modalitetskoder, leverandørnavne, kategorier for snittykkelse og standardiserede dato- og tidsformater.
Endelig bør de strukturerede metadata gemmes i et big data-miljø, såsom en relationel database, NoSQL-lager eller kolonnebaseret datasø, med indeksering for at muliggøre hurtig og effektiv søgning.
Når metadata er udtrukket, skal de gennemgå kvalitetssikring for at sikre nøjagtighed og pålidelighed. Manglende eller inkonsistente felter, såsom blanke værdier for snittykkelse, inkonsistente modalitetsmærkater eller duplikerede Study Instance UID'er, skal identificeres og korrigeres.
Privatliv og anonymisering er også kritiske på dette stadie, da metadata ofte indeholder personhenførbare oplysninger, herunder patientnavne, ID'er og datoer; afidentificeringsværktøjer og protokoller er essentielle.
Vedligeholdelse af omfattende revisionsspor er en anden vigtig praksis, der dokumenterer, hvornår metadata blev udtrukket, hvilke parserversioner der blev brugt, og eventuelle fejl, der opstod under processen.
Styringspolitikker bør også definere obligatoriske felter og give vejledning om, hvordan man håndterer ældre eller ufuldstændige datasæt for at sikre, at downstream-analyser er nøjagtige og overholder reglerne.
Det næste trin er metadata-drevet indeksering og feature engineering, som omdanner rå metadata til handlingsrettet information.
Dette indebærer oprettelse af indekser og filtre, der giver forskere og analytikere mulighed for at forespørge specifikke datasæt, f.eks. hente alle bryst-CT-scanninger med snittykkelse under 1,5 millimeter fra en bestemt leverandør inden for et givet datointerval.
Feature engineering bygger videre på dette ved at kombinere metadatafelter såsom leverandør, model, optagelsesdato, snittykkelse, konvolutionskerne, kontrastprotokol, kropsregion, strålingsdosis og institutions-ID til strukturerede variabler, der er egnede til analyse.
Metadata kan også linkes til kliniske datasæt, hvilket forbinder billeddata med patientudfald, diagnoser eller behandlinger. Denne sammenkobling giver et mere holistisk syn på billeddata og deres kliniske kontekst.
Når metadata er indekseret og features er konstrueret, bliver analyse og generering af indsigt mulig.
Beskrivende analyser kan afsløre undersøgelsesvolumener efter modalitet, leverandør eller region, spore tendenser i optagelsesparametre og fremhæve fejl eller uoverensstemmelser i billeddannelsespraksis. Sammenlignende analyser muliggør evaluering af optagelsesprotokoller på tværs af institutioner, detektering af afvigelser og identifikation af outlier-scanninger, der kan kræve særlig opmærksomhed.
For maskinlæring og AI-applikationer er metadata essentielle for at kontrollere domæneskift, sikre at trænings- og testdatasæt stratificeres passende, og kombinere pixelbaserede funktioner med strukturerede metadatavariabler. Operationelle dashboards kan derefter udnytte disse data til at overvåge arbejdsbyrde, vurdere kvalitetssikringsmålinger og sikre overholdelse af protokoller på tværs af steder.
Endelig fuldender feedback og løbende forbedring metadata-livscyklussen. Indsigter afledt af analyser kan informere om forfinelse af optagelsesprotokoller og standardisering af workflows for at forbedre den overordnede datakvalitet.
Nye billeddiagnostiske undersøgelser og metadata bør løbende indtages, med overvågning af metadatalagerets ydeevne, svartider og dataintegritet. Erfaringer bør arkiveres for at fange forudsigende metadatafelter, adressere tilbagevendende huller eller fejl og forbedre styringspraksis.
Denne iterative tilgang sikrer, at metadata-pipelines forbliver robuste, skalerbare og værdifulde for fremtidig forskning, AI-applikationer og operationel beslutningstagning.
• Leverandør/institutions-variabilitet: Private tags eller løse fortolkninger af standarder.
• Manglende eller beskadigede metadata: Ældre undersøgelser kan have ufuldstændige headere.
• Dataprivatliv & anonymisering: PHI skal afidentificeres til forskning på tværs af steder.
• Skala & ydeevne: Millioner af billeder kræver effektiv behandling og lagring.
• Domæneskift/bias: Dominerende leverandører/protokoller kan skævvride AI-modeller.
• Lovgivningsmæssige & compliance-problemer: Implementeringer i flere regioner kan involvere HIPAA, GDPR eller lokale regler.
DICOM-metadata er det skjulte skelet i billedanalyse. Platforme som PostDICOM illustrerer, hvordan man transformerer et fragmenteret arkiv af DICOM-filer til et søgbart, skalerbart, metadata-drevet økosystem. Hvis du vil udforske PostDICOM, opfordrer vi dig til at hente vores 7-dages gratis prøveperiode.
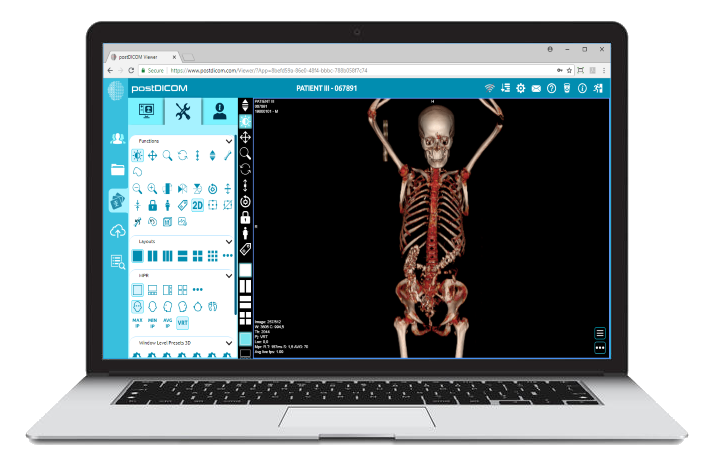
|
Cloud PACS og online DICOM ViewerUpload DICOM-billeder og kliniske dokumenter til PostDICOM-servere. Gem, vis, samarbejd og del dine medicinske billedfiler. |