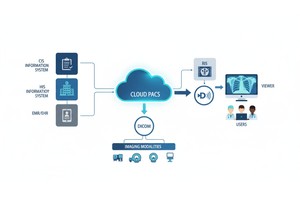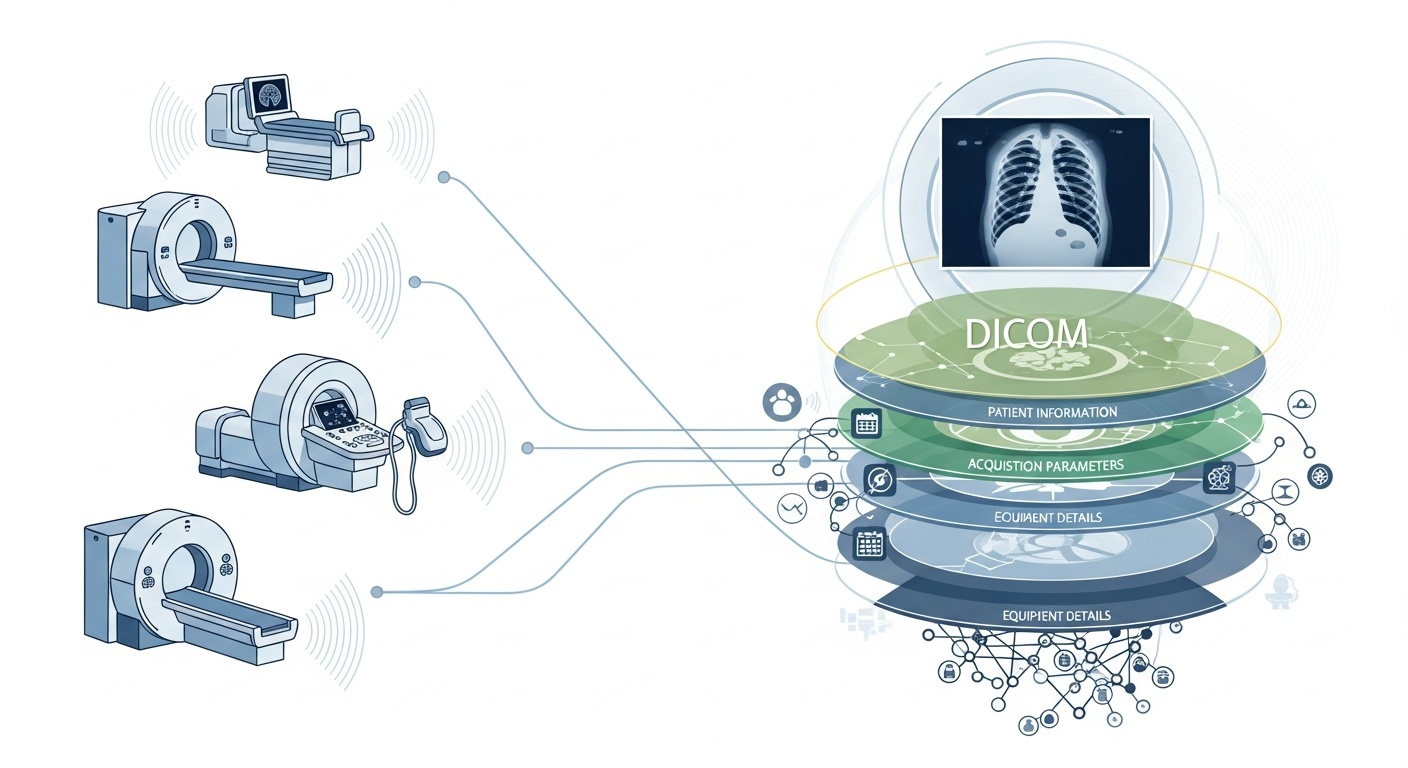
Varje gång ett radiologiteam skannar en patient, exempelvis med DT, MRT eller ultraljud, genereras en kaskad av data. Mest synlig är själva bilden, men bakom den finns ett rikt lager av metadata: vem, vad, när, hur och var skanningen gjordes. Det lagret styrs av standarden DICOM (Digital Imaging and Communications in Medicine), en standard för medicinskt bildformat som fastställdes av National Electrical Manufacturers Association (NEMA) och American College of Radiology (ACR) för årtionden sedan.
Det som gör metadatan så intressant är att den är strukturerad, maskinläsbar och anmärkningsvärt detaljerad: utrustningsinställningar, insamlingsparametrar, patientdemografi, studie-ID, till och med institutionskoder och information om modalitetstillverkare. Denna rikedom är vad som möjliggör big data-analys, vidare forskning, AI-modellering och protokollstandardisering om du utnyttjar den väl.
I samband med big data talar vi inte bara om några dussin bildstudier. Vi talar om hundratusentals, eller till och med miljontals, bilder över olika modaliteter, platser och leverantörer, med metadata som det viktigaste indexeringslagret: "vem & när & hur" för varje objekt. Utan att effektivt utnyttja metadata riskerar du att ha ett massivt arkiv med bilder men minimal förmåga att söka, jämföra eller härleda insikter från dem. En nyligen genomförd granskning konstaterar: "majoriteten av informationen som lagras i PACS-arkiv nås aldrig igen", en bortkastad möjlighet.
Säg att du driver en studie på flera platser av lung-DT-skanningar för tidig upptäckt av emfysem. Du vill välja skanningar baserat på parametrar: skannerleverantör/märke/modell, snittjocklek, rekonstruktionskärna, patientens ålder, datumintervall, kanske till och med dosparametrar. De flesta av dessa är metadatafält, inte pixeldata. Genom att extrahera dessa taggar kan du bygga kohorten, utesluta inkompatibla skanningar (t.ex. för tjocka snitt) och säkerställa jämförbarhet.
Metadata låter dig övervaka själva bildbehandlingsprocessen: använder institutionen rätt protokoll? Avviker insamlingsparametrarna över tid (t.ex. synfält, timing för kontrastinjektion)? Är leverantörsinställningarna konsekventa? I en big data-värld där tusentals skanningar sker per dag kan du inte förlita dig på visuell granskning. Du behöver analys av metadata. Många PACS-system underutnyttjar metadata av denna anledning.
Om du bygger en AI- eller radiomik-pipeline kan du inte behandla varje bild som utbytbar. Metadata blir en integrerad kontrollvariabel: inmatningsfunktioner inkluderar ofta modalitet, kVp (kilovolt peak), tillverkare, kärna, snittjocklek, och till och med datum eller sjukhus kan spela roll (domänskifte). Dessa metadatafält hjälper till att hantera bias, harmonisera data och kommentera bilder med kontext. Många forskare kallar metadata "lika viktigt som pixeldata."
Big data innebär stor skala. Det innebär varierade källor, flera leverantörer, olika institutioner och heterogena format. DICOM-metadata är det standardiserade "språket" som hjälper till att ena metadatalagret, möjliggöra sökning/indexering, säkerställa interoperabilitet och bygga skalbara arkitekturer (Cloud PACS, federerade arkiv). Men implementeringen spelar roll. Samma PMC-studie fann att många system inte utnyttjar standarden fullt ut.
PostDICOM erbjuder ett molnbaserat PACS (Picture Archiving and Communication System) för lagring, visning och delning av bildstudier och kliniska dokument. Några viktiga metadatarelevanta funktioner i PostDICOM:
• Stöd för DICOM-taggar & beskrivningar: Vårt resursbibliotek listar "DICOM-modalitet & Taggar", vilket ger användare tillgång till tagglistor och beskrivningar.DICOM-modalitet & Taggar
• API / FHIR-integration: Det stöder API- och FHIR-gränssnitt (Fast Healthcare Interoperability Resources), vilket gör att metadata kan efterfrågas programmatiskt, integreras med andra system och analyseras.
• Molnskalbarhet & delning mellan flera platser: Delning mellan patienter, läkare, institutioner; obegränsad skalbarhet innebär att big data-pipelines blir genomförbara.
• Avancerad bildbehandling & multimodalt stöd: Även om detta rör pixlar, innebär stödet för modaliteter som PET–DT och multiserier att metadatan är omfattande (SUV-värden, fusionsvolymer, modalitetstyp) och tillgänglig för analys.
Genom att använda en plattform som PostDICOM kan du utnyttja metadata genom strukturerade arbetsflöden, API:er och molnarkitektur.
Här är hur man strukturerar arbetsflödet från råa arkiv till analysfärdiga insikter.
 - Created by PostDICOM.jpg)
Det första steget i att utnyttja DICOM-metadata för analys är extrahering och normalisering. Bibliotek som det öppna Python-paketet PyDicom används vanligtvis för att tolka DICOM-filer och extrahera relevanta taggar, inklusive bildrader och kolumner, konvolutionskärnor och modalitetsspecifika insamlingsparametrar.
Att hantera heterogenitet är avgörande, eftersom olika leverantörer ofta använder privata taggar eller icke-standardiserade implementeringar. Robust tolkning, reservlogik och omfattande taggmappningstabeller krävs för att säkerställa konsekvens över dataset.
När den extraherats måste metadatan normaliseras och mappas till standardontologier och strukturer, såsom modalitetskoder, leverantörsnamn, snittjocklekskategorier samt standardiserade datum- och tidsformat.
Slutligen bör den strukturerade metadatan lagras i en big data-miljö, såsom en relationsdatabas, NoSQL-lagring eller kolumnbaserad datasjö, med indexering för att möjliggöra snabba och effektiva sökningar.
När metadatan har extraherats måste den genomgå kvalitetssäkring för att säkerställa noggrannhet och tillförlitlighet. Saknade eller inkonsekventa fält, såsom tomma värden för snittjocklek, inkonsekventa modalitetsetiketter eller duplicerade studieinstans-UID:n, måste identifieras och korrigeras.
Integritet och anonymisering är också kritiska i detta skede, eftersom metadata ofta innehåller personligt identifierbar information inklusive patientnamn, ID:n och datum; avidentifieringsverktyg och protokoll är nödvändiga.
Att upprätthålla omfattande granskningsspår är en annan viktig praxis, som dokumenterar när metadata extraherades, vilka tolkversioner som användes och eventuella fel som uppstod under processen.
Styrningspolicyer bör också definiera obligatoriska fält och ge vägledning om hur man hanterar äldre eller ofullständiga dataset för att säkerställa att efterföljande analyser är korrekta och regelefterlevande.
Nästa steg är metadatadriven indexering och särdragskonstruktion (feature engineering), som omvandlar rå metadata till handlingsbar information.
Detta innebär att skapa index och filter som låter forskare och analytiker söka i specifika dataset, till exempel hämta alla lung-DT-skanningar med snittjocklek under 1,5 millimeter från en viss leverantör inom ett givet datumintervall.
Särdragskonstruktion bygger på detta genom att kombinera metadatafält som leverantör, modell, insamlingsdatum, snittjocklek, konvolutionskärna, kontrastprotokoll, kroppsregion, stråldos och institutions-ID till strukturerade variabler lämpliga för analys.
Metadata kan också kopplas till kliniska dataset, vilket kopplar bilddata till patientutfall, diagnoser eller behandlingar. Denna koppling möjliggör en mer holistisk bild av bilddata och dess kliniska kontext.
När metadata är indexerad och särdrag är konstruerade blir analys och generering av insikter möjlig.
Beskrivande analys kan avslöja studievolymer efter modalitet, leverantör eller region, spåra trender i insamlingsparametrar och lyfta fram fel eller inkonsekvenser i bildbehandlingsrutiner. Jämförande analys möjliggör utvärdering av insamlingsprotokoll över institutioner, upptäckt av avvikelser och identifiering av avvikande skanningar som kan kräva särskild uppmärksamhet.
För maskininlärning och AI-tillämpningar är metadata avgörande för att kontrollera domänskifte, säkerställa att tränings- och testdataset stratifieras lämpligt, och kombinera pixelbaserade särdrag med strukturerade metadatavariabler. Operativa instrumentpaneler kan sedan utnyttja denna data för att övervaka arbetsbelastning, bedöma kvalitetssäkringsmått och säkerställa protokollefterlevnad över platser.
Slutligen fullbordar återkoppling och ständig förbättring metadatalivscykeln. Insikter som härleds från analyser kan informera förfining av insamlingsprotokoll och standardisering av arbetsflöden för att förbättra den totala datakvaliteten.
Nya bildstudier och metadata bör kontinuerligt matas in, med övervakning av metadatalagrets prestanda, söktider och dataintegritet. Lärdomar bör arkiveras för att fånga prediktiva metadatafält, åtgärda återkommande luckor eller fel och förbättra styrningsmetoder.
Detta iterativa tillvägagångssätt säkerställer att metadatapipelines förblir robusta, skalbara och värdefulla för framtida forskning, AI-tillämpningar och operativt beslutsfattande.
• Leverantörs-/institutionsvariabilitet: Privata taggar eller lösa tolkningar av standarder.
• Saknad eller korrupt metadata: Äldre studier kan ha ofullständiga rubriker.
• Datasekretess & Anonymisering: PHI (skyddad hälsoinformation) måste avidentifieras för forskning på flera platser.
• Skala & Prestanda: Miljontals bilder kräver effektiv behandling och lagring.
• Domänskifte/bias: Dominerande leverantörer/protokoll kan snedvrida AI-modeller.
• Regulatoriska frågor & Efterlevnad: Utplacering i flera regioner kan involvera HIPAA, GDPR eller lokala föreskrifter.
DICOM-metadata är det dolda skelettet i bildanalys. Plattformar som PostDICOM illustrerar hur man omvandlar ett fragmenterat arkiv av DICOM-filer till ett sökbart, skalbart, metadatadrivet ekosystem. Om du vill utforska PostDICOM rekommenderar vi att du skaffar vår 7-dagars gratis provperiod.
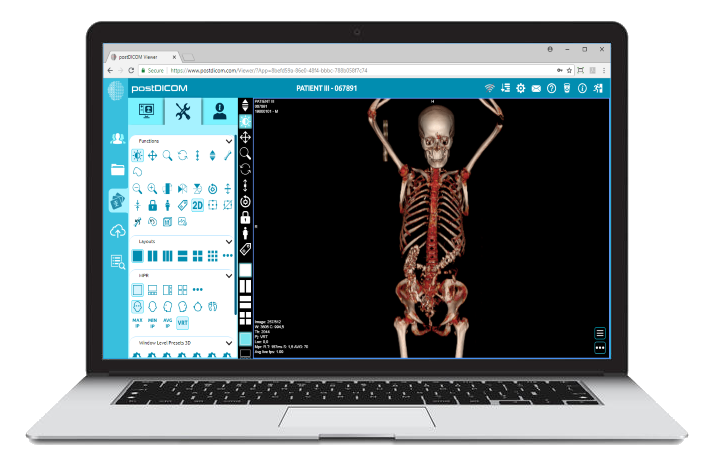
|
Cloud PACS och Online DICOM-visareLadda upp DICOM-bilder och kliniska dokument till PostDICOM-servrar. Lagra, visa, samarbeta och dela dina medicinska bildfiler. |