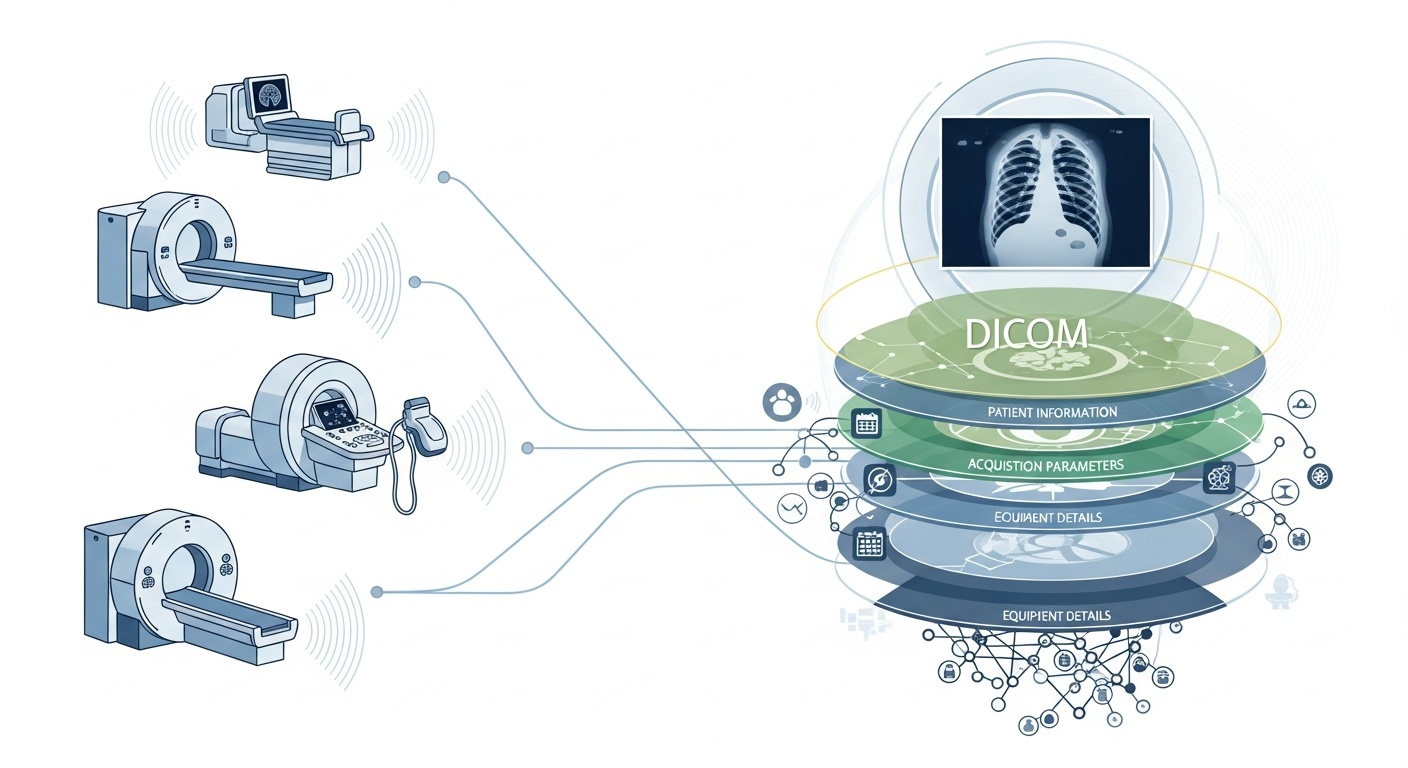
Ogni volta che un team di radiologia scansiona un paziente, ad esempio per una TC, una RM o un'ecografia, viene generata una cascata di dati. L'elemento più visibile è l'immagine stessa, ma dietro di essa c'è un ricco strato di metadati: chi, cosa, quando, come e dove della scansione. Questo livello è governato dallo standard DICOM (Digital Imaging and Communications in Medicine), uno standard di formato per l'imaging medico consolidato dalla National Electrical Manufacturers Association (NEMA) e dall'American College of Radiology (ACR) decenni fa.
Ciò che rende i metadati così interessanti è che sono strutturati, leggibili dalla macchina e straordinariamente dettagliati: impostazioni dell'attrezzatura, parametri di acquisizione, dati demografici del paziente, ID dello studio, persino codici dell'istituzione e dettagli del produttore della modalità. Questa ricchezza è ciò che consente l'analisi dei big data, la ricerca a valle, la modellazione AI e la standardizzazione dei protocolli, se sfruttata correttamente.
Nel contesto dei big data, non stiamo parlando solo di alcune dozzine di studi di imaging. Parliamo di centinaia di migliaia, o addirittura milioni, di immagini attraverso modalità, siti e fornitori, con i metadati come strato chiave di indicizzazione: il "chi, quando e come" di ogni elemento. Senza utilizzare efficacemente i metadati, si rischia di avere un enorme archivio di immagini ma una capacità minima di interrogarle, confrontarle o trarne informazioni. Una recente revisione afferma: "la maggior parte delle informazioni archiviate negli archivi PACS non viene mai più consultata", un'opportunità sprecata.
Supponiamo che Lei stia conducendo uno studio multisito su scansioni TC polmonari per la rilevazione precoce dell'enfisema. Vorrà selezionare le scansioni in base a parametri: fornitore/marca/modello dello scanner, spessore dello strato, kernel di ricostruzione, età del paziente, intervalli di date, forse anche parametri di dose. La maggior parte di questi sono campi di metadati, non dati pixel. L'estrazione di questi tag Le consente di costruire la coorte, escludere scansioni incompatibili (ad esempio, strati troppo spessi) e garantire la comparabilità.
I metadati consentono di monitorare il processo di imaging stesso: l'istituzione sta utilizzando il protocollo corretto? I parametri di acquisizione stanno deviando nel tempo (ad esempio, campo visivo, tempistica dell'iniezione del mezzo di contrasto)? Le impostazioni del fornitore sono coerenti? In un mondo di big data dove avvengono migliaia di scansioni al giorno, non ci si può affidare all'ispezione visiva umana. È necessaria l'analisi sui metadati. Molti sistemi PACS sfruttano insufficientemente i metadati per questo motivo.
Se si costruisce una pipeline di AI o radiomica, non si può trattare ogni immagine come intercambiabile. I metadati diventano una variabile di controllo integrale: le feature di input spesso includono modalità, kVp (kilovoltaggio di picco), produttore, kernel, spessore dello strato e persino la data o l'ospedale possono essere importanti (domain shift). Questi campi di metadati aiutano a gestire i bias, armonizzare i dati e annotare le immagini con il contesto. Molti ricercatori definiscono i metadati "importanti quanto i dati dei pixel".
Big data significa scala. Ciò implica fonti varie, molteplici fornitori, diverse istituzioni e formati eterogenei. I metadati DICOM sono il "linguaggio" standardizzato che aiuta a unificare lo strato dei metadati, abilitare ricerca/indicizzazione, garantire l'interoperabilità e costruire architetture scalabili (Cloud PACS, archivi federati). Ma l'implementazione è importante. Lo stesso studio PMC ha rilevato che molti sistemi non sfruttano appieno lo standard.
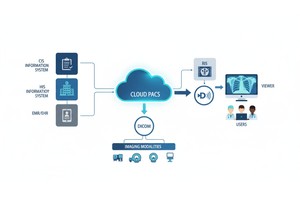
PostDICOM offre un PACS (Picture Archiving and Communication System) basato su cloud per l'archiviazione, la visualizzazione e la condivisione di studi di imaging e documenti clinici. Alcune funzionalità chiave rilevanti per i metadati di PostDICOM:
• Supporto per tag e descrizioni DICOM: La nostra libreria di risorse elenca "Modalità e tag DICOM", consentendo agli utenti di accedere agli elenchi dei tag e alle descrizioni.Modalità e tag DICOM
• Integrazione API / FHIR: Supporta interfacce API e FHIR (Fast Healthcare Interoperability Resources), consentendo ai metadati di essere interrogati programmaticamente, integrati con altri sistemi e analizzati.
• Scalabilità cloud e condivisione multisito: La condivisione tra pazienti, medici e istituzioni; scalabilità illimitata significa che le pipeline di big data diventano fattibili.
• Elaborazione avanzata delle immagini e supporto multimodale: Sebbene ciò riguardi i pixel, il supporto di modalità come PET–TC e serie multiple significa che i metadati sono sostanziali (valori SUV, volumi di fusione, tipo di modalità) e disponibili per l'analisi.
L'utilizzo di una piattaforma come PostDICOM Le consente di sfruttare i metadati attraverso flussi di lavoro strutturati, API e architettura cloud.
Ecco come strutturare il flusso di lavoro dagli archivi grezzi agli insight pronti per l'analisi.
 - Created by PostDICOM.jpg)
Il primo passo per sfruttare i metadati DICOM per l'analisi è l'estrazione e la normalizzazione. Librerie come il pacchetto open-source Python PyDicom sono comunemente utilizzate per analizzare i file DICOM ed estrarre i tag rilevanti, inclusi righe e colonne dell'immagine, kernel di convoluzione e parametri di acquisizione specifici della modalità.
Gestire l'eterogeneità è fondamentale, poiché diversi fornitori utilizzano spesso tag privati o implementazioni non standard. Sono necessari parsing robusto, logica di fallback e tabelle di mappatura dei tag complete per garantire la coerenza tra i set di dati.
Una volta estratti, i metadati devono essere normalizzati e mappati a ontologie e strutture standard, come codici di modalità, nomi dei fornitori, categorie di spessore dello strato e formati di data e ora standardizzati.
Infine, i metadati strutturati dovrebbero essere archiviati in un ambiente big data, come un database relazionale, un archivio NoSQL o un data lake colonnare, con indicizzazione per consentire interrogazioni rapide ed efficienti.
Una volta estratti, i metadati devono essere sottoposti a controllo di qualità per garantirne l'accuratezza e l'affidabilità. Campi mancanti o incoerenti, come valori di spessore dello strato vuoti, etichette di modalità incoerenti o UID dell'istanza di studio duplicati, devono essere identificati e corretti.
La privacy e l'anonimizzazione sono anch'esse critiche in questa fase, poiché i metadati contengono spesso informazioni di identificazione personale inclusi nomi dei pazienti, ID e date; strumenti e protocolli di de-identificazione sono essenziali.
Mantenere tracce di controllo (audit trail) complete è un'altra pratica importante, documentando quando i metadati sono stati estratti, quali versioni del parser sono state utilizzate ed eventuali errori riscontrati durante il processo.
Le politiche di governance dovrebbero anche definire i campi obbligatori e fornire indicazioni su come gestire dataset legacy o incompleti per garantire che le analisi a valle siano accurate e conformi.
Il passo successivo è l'indicizzazione guidata dai metadati e l'ingegneria delle feature, che trasforma i metadati grezzi in informazioni azionabili.
Ciò comporta la creazione di indici e filtri che consentono a ricercatori e analisti di interrogare set di dati specifici, ad esempio, recuperando tutte le scansioni TC del torace con spessore dello strato inferiore a 1,5 millimetri da un particolare fornitore entro un determinato intervallo di date.
L'ingegneria delle feature si basa su questo combinando campi di metadati come fornitore, modello, data di acquisizione, spessore dello strato, kernel di convoluzione, protocollo di contrasto, regione corporea, dose di radiazioni e ID dell'istituzione in variabili strutturate adatte all'analisi.
I metadati possono anche essere collegati a set di dati clinici, connettendo i dati di imaging agli esiti dei pazienti, alle diagnosi o ai trattamenti. Questo collegamento consente una visione più olistica dei dati di imaging e del loro contesto clinico.
Una volta che i metadati sono indicizzati e le feature sono ingegnerizzate, l'analisi e la generazione di insight diventano possibili.
L'analisi descrittiva può rivelare volumi di studio per modalità, fornitore o regione, tracciare le tendenze nei parametri di acquisizione ed evidenziare errori o incongruenze nelle pratiche di imaging. L'analisi comparativa consente la valutazione dei protocolli di acquisizione tra le istituzioni, il rilevamento di deviazioni e l'identificazione di scansioni anomale che potrebbero richiedere un'attenzione speciale.
Per le applicazioni di machine learning e AI, i metadati sono essenziali per controllare il domain shift, garantendo che i set di dati di addestramento e test siano stratificati in modo appropriato e combinando feature basate sui pixel con variabili di metadati strutturate. Le dashboard operative possono quindi sfruttare questi dati per monitorare il carico di lavoro, valutare le metriche di garanzia della qualità e assicurare la conformità al protocollo tra i siti.
Infine, il feedback e il miglioramento continuo completano il ciclo di vita dei metadati. Gli insight derivati dall'analisi possono informare il perfezionamento dei protocolli di acquisizione e la standardizzazione dei flussi di lavoro per migliorare la qualità complessiva dei dati.
Nuovi studi di imaging e metadati dovrebbero essere ingeriti continuamente, con il monitoraggio delle prestazioni dell'archivio dei metadati, dei tempi di interrogazione e dell'integrità dei dati. Le lezioni apprese dovrebbero essere archiviate per catturare campi di metadati predittivi, affrontare lacune o errori ricorrenti e migliorare le pratiche di governance.
Questo approccio iterativo garantisce che le pipeline di metadati rimangano robuste, scalabili e preziose per la ricerca futura, le applicazioni AI e il processo decisionale operativo.
• Variabilità fornitore/istituzione: Tag privati o interpretazioni standard vaghe.
• Metadati mancanti o corrotti: Gli studi più vecchi potrebbero avere intestazioni incomplete.
• Privacy dei dati e anonimizzazione: Le PHI (informazioni sanitarie protette) devono essere de-identificate per la ricerca multisito.
• Scala e prestazioni: Milioni di immagini richiedono un'elaborazione e un'archiviazione efficienti.
• Domain Shift/bias: Fornitori/protocolli dominanti possono distorcere i modelli AI.
• Problemi normativi e di conformità: Le implementazioni multi-regione possono coinvolgere HIPAA, GDPR o normative locali.
I metadati DICOM sono lo scheletro nascosto dell'analisi dell'imaging. Piattaforme come PostDICOM illustrano come trasformare un archivio frammentato di file DICOM in un ecosistema ricercabile, scalabile e guidato dai metadati. Se desidera esplorare PostDICOM, La invitiamo a ottenere la nostra prova gratuita di 7 giorni.
|
Cloud PACS e Visualizzatore DICOM OnlineCarichi immagini DICOM e documenti clinici sui server PostDICOM. Archivi, visualizzi, collabori e condivida i Suoi file di imaging medico. |