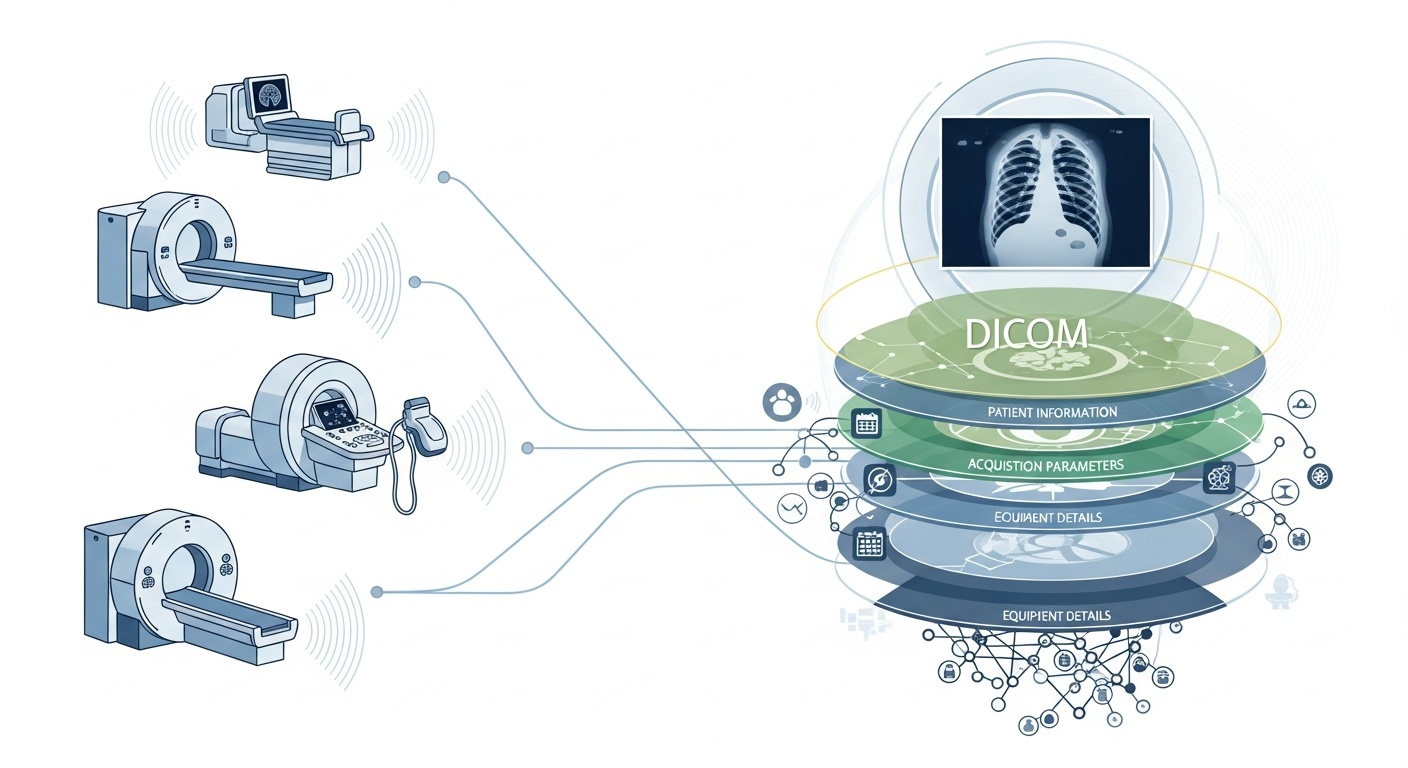
Joka kerta, kun radiologiatiimi kuvaa potilaan, esimerkiksi TT:n, MRI:n tai ultraäänen, syntyy valtava määrä dataa. Näkyvin osa on itse kuva, mutta sen taustalla on rikas metatietokerros: kuvauksen kuka, mitä, milloin, miten ja missä. Tätä kerrosta hallitsee standardi DICOM (Digital Imaging and Communications in Medicine), lääketieteellisen kuvantamisen muotostandardi, jonka National Electrical Manufacturers Association (NEMA) ja American College of Radiology (ACR) loivat vuosikymmeniä sitten.
Metatiedoista tekee mielenkiintoisia se, että ne ovat rakenteellisia, koneellisesti luettavia ja huomattavan yksityiskohtaisia: laiteasetukset, hankintaparametrit, potilaan demografiset tiedot, tutkimustunnisteet, jopa laitoskoodit ja modaliteetin valmistajan tiedot. Tämä rikkaus mahdollistaa massadata-analytiikan, jatkotutkimuksen, tekoälymallinnuksen ja protokollien standardoinnin, jos sitä hyödynnetään oikein.
Massadatan yhteydessä emme puhu vain muutamista kymmenistä kuvantamistutkimuksista. Puhumme sadoista tuhansista tai jopa miljoonista kuvista eri modaliteeteissa, toimipisteissä ja toimittajissa, joissa metadata toimii keskeisenä indeksointikerroksena: kunkin kohteen "kuka & milloin & miten". Ilman metatietojen tehokasta hyödyntämistä vaarana on massiivinen kuva-arkisto, josta on vain vähän mahdollisuuksia tehdä hakuja, vertailuja tai johtaa oivalluksia. Tuoreen katsauksen mukaan "suurinta osaa PACS-arkistoihin tallennetusta tiedosta ei koskaan käytetä uudelleen", mikä on hukattu mahdollisuus.
Oletetaan, että suoritat usean toimipisteen tutkimusta keuhkojen TT-kuvista varhaisen emfyseeman havaitsemiseksi. Haluat valita kuvaukset parametrien perusteella: laitevalmistaja/-merkki/-malli, leikepaksuus, rekonstruktiokernel, potilaan ikä, päivämäärät, kenties jopa annosparametrit. Useimmat näistä ovat metatietokenttiä, eivät pikselidataa. Näiden tunnisteiden poimiminen mahdollistaa kohortin rakentamisen, yhteensopimattomien kuvausten poissulkemisen (esim. liian paksut leikkeet) ja vertailukelpoisuuden varmistamisen.
Metatietojen avulla voit seurata itse kuvantamisprosessia: käyttääkö laitos oikeaa protokollaa? Poikkeavatko hankintaparametrit ajan myötä (esim. kuvausala, varjoaineen injektioajoitus)? Ovatko toimittajan asetukset johdonmukaisia? Massadatamaailmassa, jossa tapahtuu tuhansia kuvauksia päivässä, ei voida luottaa ihmisen silmämääräiseen tarkasteluun. Tarvitaan analytiikkaa metatiedoista. Monet PACS-järjestelmät hyödyntävät metatietoja puutteellisesti tästä syystä.
Jos rakennat tekoäly- tai radiomiikkaputkea, et voi kohdella jokaista kuvaa vaihtokelpoisena. Metadatasta tulee olennainen kontrollimuuttuja: syötepiirteisiin kuuluvat usein modaliteetti, kVp (kilovolttihuippu), valmistaja, kernel, leikepaksuus ja jopa päivämäärä tai sairaala voivat olla merkityksellisiä (domain shift). Nämä metatietokentät auttavat hallitsemaan vääristymiä, harmonisoimaan dataa ja annotoimaan kuvia kontekstilla. Monet tutkijat kutsuvat metadataa "yhtä tärkeäksi kuin pikselidataa".
Massadata tarkoittaa mittakaavaa. Se edellyttää vaihtelevia lähteitä, useita toimittajia, eri laitoksia ja heterogeenisia muotoja. DICOM-metadata on standardoitu "kieli", joka auttaa yhtenäistämään metatietokerroksen, mahdollistamaan haun/indeksoinnin, varmistamaan yhteentoimivuuden ja rakentamaan skaalautuvia arkkitehtuureja (Cloud PACS, federaatioarkistot). Mutta toteutuksella on väliä. Sama PMC-tutkimus havaitsi, että monet järjestelmät eivät hyödynnä standardia täysimääräisesti.
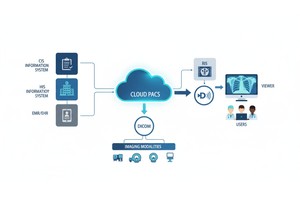
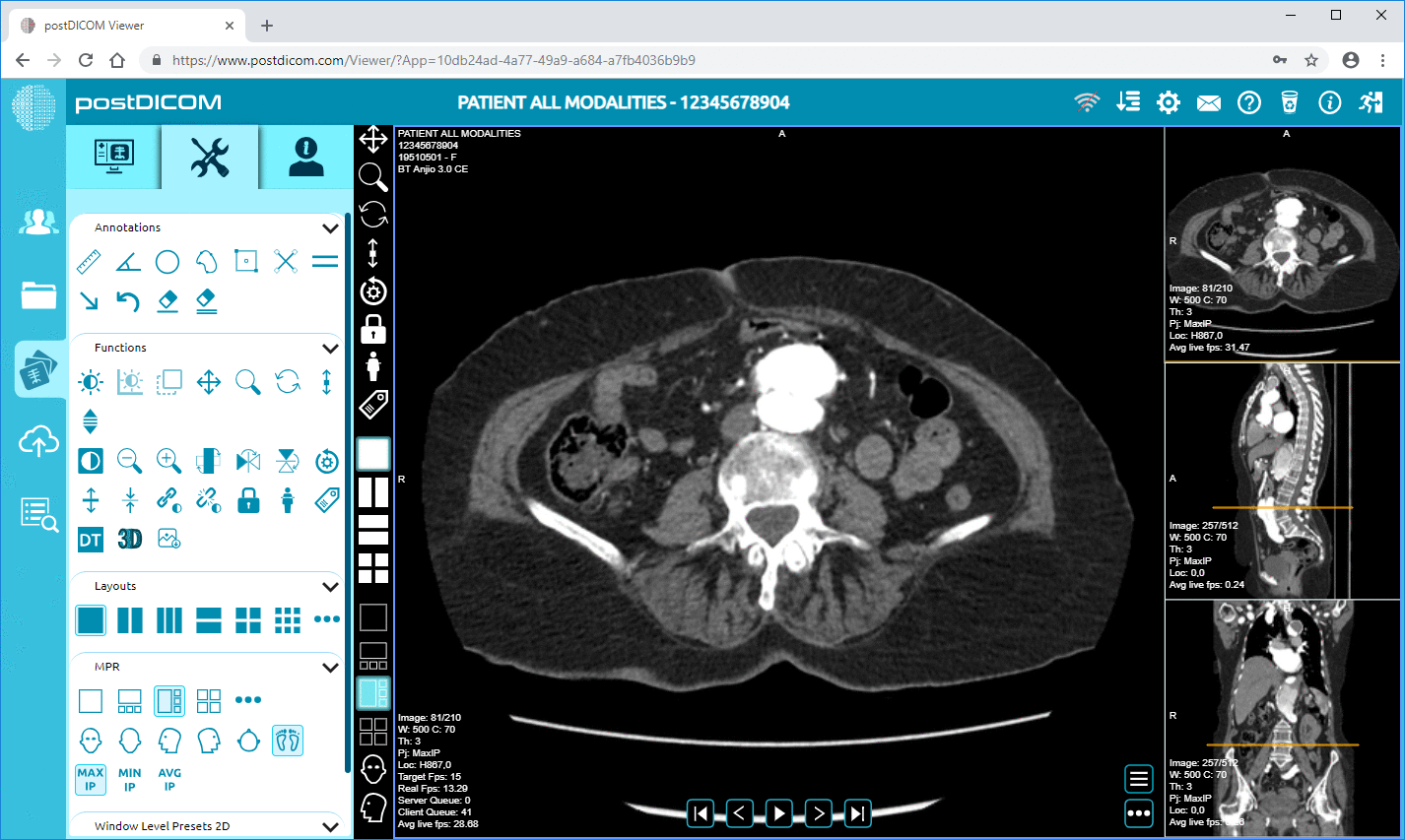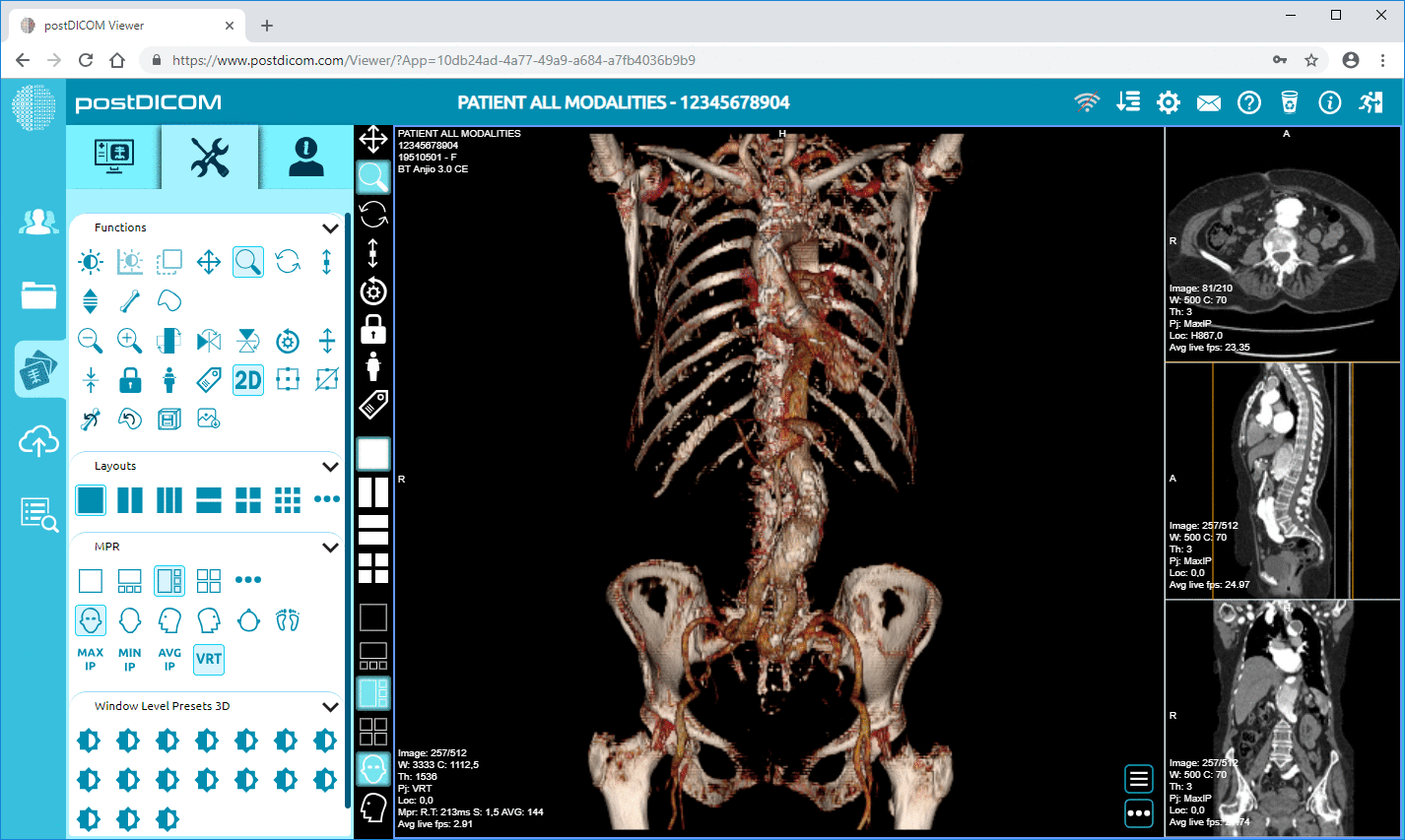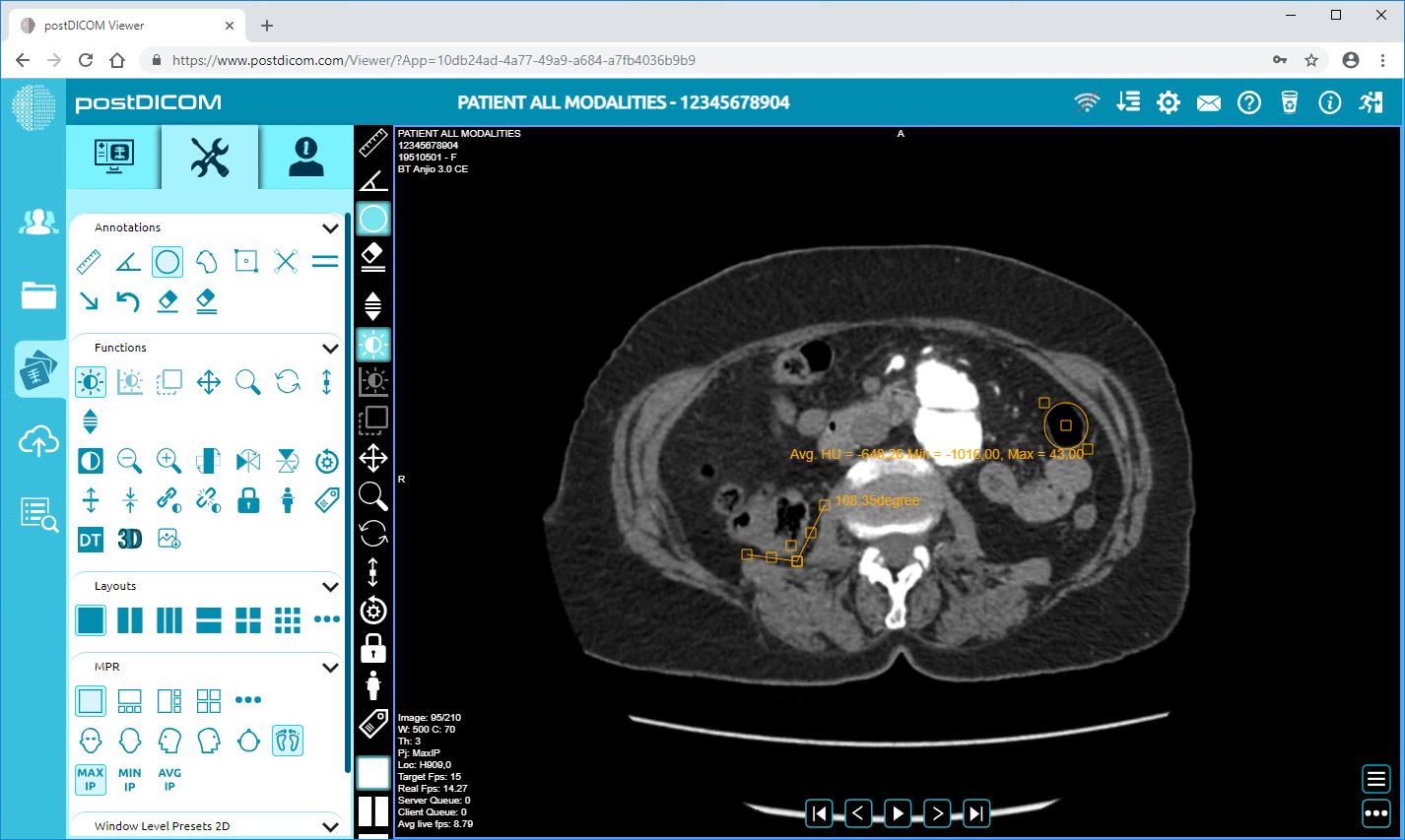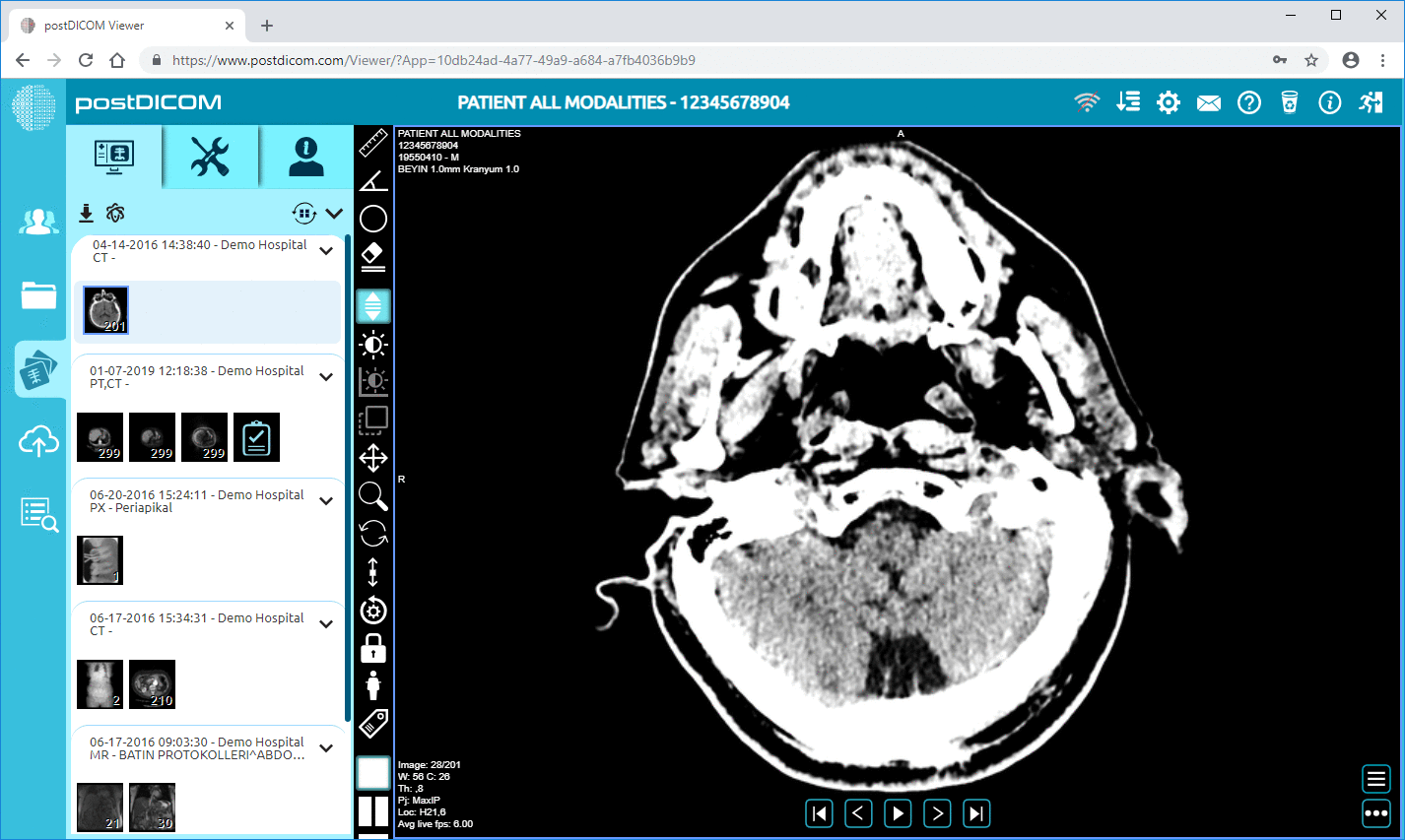
PostDICOM tarjoaa pilvipohjaisen PACS-järjestelmän (Picture Archiving and Communication System) kuvantamistutkimusten ja kliinisten asiakirjojen tallentamiseen, katseluun ja jakamiseen. Joitakin PostDICOMin keskeisiä metatietoihin liittyviä ominaisuuksia:
• Tuki DICOM-tunnisteille ja -kuvauksille: Resurssikirjastomme listaa "DICOM-modaliteetit ja tunnisteet", jolloin käyttäjät pääsevät käsiksi tunnistelistoihin ja kuvauksiin.DICOM-modaliteetti ja tunnisteet
• API / FHIR -integraatio: Se tukee API- ja FHIR-rajapintoja (Fast Healthcare Interoperability Resources), jolloin metadataa voidaan kysellä ohjelmallisesti, integroida muihin järjestelmiin ja analysoida.
• Pilven skaalautuvuus ja jakaminen useiden toimipisteiden välillä: Jakaminen potilaiden, lääkäreiden ja laitosten välillä; rajoittamaton skaalautuvuus tarkoittaa, että massadataputkista tulee toteuttamiskelpoisia.
• Edistynyt kuvankäsittely ja monimuotoisuustuki: Vaikka tämä koskee pikseleitä, tuki modaliteeteille kuten PET–TT ja monisarjakuvaus tarkoittaa, että metadata on merkittävää (SUV-arvot, fuusiotilavuudet, modaliteettityyppi) ja saatavilla analytiikkaa varten.
PostDICOMin kaltaisen alustan käyttö mahdollistaa metatietojen hyödyntämisen jäsenneltyjen työnkulkujen, APIen ja pilviarkkitehtuurin kautta.
Näin rakennat työnkulun raaka-arkistoista analytiikkavalmiisiin oivalluksiin.
 - Created by PostDICOM.jpg)
Ensimmäinen askel DICOM-metatietojen hyödyntämisessä analytiikassa on poiminta ja normalisointi. Kirjastoja, kuten avoimen lähdekoodin Python-pakettia PyDicom, käytetään yleisesti DICOM-tiedostojen jäsentämiseen ja relevanttien tunnisteiden poimimiseen, mukaan lukien kuvarivit ja -sarakkeet, konvoluutiokernelit ja modaliteettikohtaiset hankintaparametrit.
Heterogeenisyyden hallinta on ratkaisevaa, sillä eri toimittajat käyttävät usein yksityisiä tunnisteita tai epästandardeja toteutuksia. Vankka jäsentäminen, varajärjestelyt ja kattavat tunnistekartoitustaulukot ovat tarpeen johdonmukaisuuden varmistamiseksi eri tietosarjoissa.
Poiminnan jälkeen metadata on normalisoitava ja kartoitettava standardiontologioihin ja -rakenteisiin, kuten modaliteettikoodeihin, toimittajien nimiin, leikepaksuusluokkiin sekä standardoituihin päivämäärä- ja aikamuotoihin.
Lopuksi jäsennelty metadata tulisi tallentaa massadataympäristöön, kuten relaatiotietokantaan, NoSQL-varastoon tai sarakemuotoiseen data lake -ratkaisuun, jossa on indeksointi nopeita ja tehokkaita hakuja varten.
Poiminnan jälkeen metatiedoille on tehtävä laadunvarmistus tarkkuuden ja luotettavuuden takaamiseksi. Puuttuvat tai epäjohdonmukaiset kentät, kuten tyhjät leikepaksuusarvot, epäjohdonmukaiset modaliteettimerkinnät tai päällekkäiset Study Instance UID -tunnisteet, on tunnistettava ja korjattava.
Yksityisyys ja anonymisointi ovat myös kriittisiä tässä vaiheessa, sillä metadata sisältää usein henkilökohtaisia tunnistetietoja, kuten potilaiden nimiä, tunnuksia ja päivämääriä; tunnisteettomaksi tekemisen työkalut ja protokollat ovat välttämättömiä.
Kattavien kirjausketjujen ylläpitäminen on toinen tärkeä käytäntö, jossa dokumentoidaan, milloin metadata poimittiin, mitä jäsennysversioita käytettiin ja mitä virheitä prosessin aikana kohdattiin.
Hallintokäytäntöjen tulisi myös määritellä pakolliset kentät ja antaa ohjeita vanhojen tai epätäydellisten tietosarjojen käsittelystä, jotta jatkojalostettu analytiikka on tarkkaa ja vaatimustenmukaista.
Seuraava vaihe on metatietopohjainen indeksointi ja piirteiden suunnittelu (feature engineering), joka muuttaa raakametadatan toimintakelpoiseksi tiedoksi.
Tämä tarkoittaa indeksien ja suodattimien luomista, joiden avulla tutkijat ja analyytikot voivat hakea tiettyjä tietosarjoja, esimerkiksi kaikki rintakehän TT-kuvaukset, joissa leikepaksuus on alle 1,5 millimetriä tietyltä toimittajalta tietyllä aikavälillä.
Piirteiden suunnittelu rakentuu tämän päälle yhdistämällä metatietokenttiä, kuten toimittaja, malli, hankintapäivämäärä, leikepaksuus, konvoluutiokernel, kontrastiaineprotokolla, kehon alue, säteilyannos ja laitostunnus, analyysiin soveltuviksi rakenteellisiksi muuttujiksi.
Metadata voidaan myös linkittää kliinisiin tietosarjoihin, yhdistäen kuvantamistiedot potilastuloksiin, diagnooseihin tai hoitoihin. Tämä linkitys mahdollistaa kokonaisvaltaisemman näkymän kuvantamistietoihin ja niiden kliiniseen kontekstiin.
Kun metadata on indeksoitu ja piirteet suunniteltu, analytiikka ja oivallusten luominen tulevat mahdollisiksi.
Kuvaileva analytiikka voi paljastaa tutkimusmäärät modaliteetin, toimittajan tai alueen mukaan, seurata hankintaparametrien trendejä ja korostaa virheitä tai epäjohdonmukaisuuksia kuvantamiskäytännöissä. Vertaileva analytiikka mahdollistaa hankintaprotokollien arvioinnin eri laitoksissa, poikkeamien havaitsemisen ja erityistä huomiota vaativien poikkeavien kuvausten tunnistamisen.
Koneoppimis- ja tekoälysovelluksissa metadata on välttämätöntä domain shift -ilmiön hallitsemiseksi, koulutus- ja testitietosarjojen asianmukaisen osituksen varmistamiseksi ja pikselipohjaisten piirteiden yhdistämiseksi rakenteellisiin metatietomuuttujiin. Operatiiviset mittaristot voivat sitten hyödyntää tätä dataa työkuorman seurantaan, laadunvarmistusmittareiden arviointiin ja protokollan noudattamisen varmistamiseen eri toimipisteissä.
Lopuksi palaute ja jatkuva parantaminen täydentävät metatietojen elinkaaren. Analytiikasta saadut oivallukset voivat ohjata hankintaprotokollien hienosäätöä ja työnkulkujen standardointia datan yleisen laadun parantamiseksi.
Uusia kuvantamistutkimuksia ja metadataa tulisi syöttää jatkuvasti järjestelmään, samalla seuraten metatietovaraston suorituskykyä, hakuaikoja ja datan eheyttä. Opitut asiat tulisi arkistoida ennakoivien metatietokenttien tallentamiseksi, toistuvien puutteiden tai virheiden korjaamiseksi ja hallintokäytäntöjen parantamiseksi.
Tämä iteratiivinen lähestymistapa varmistaa, että metatietoputket pysyvät vakaina, skaalautuvina ja arvokkaina tulevaa tutkimusta, tekoälysovelluksia ja operatiivista päätöksentekoa varten.
• Toimittaja-/laitosvaihtelu: Yksityiset tunnisteet tai väljät standarditulkinnat.
• Puuttuva tai korruptoitunut metadata: Vanhemmissa tutkimuksissa voi olla epätäydelliset otsikot.
• Tietosuoja ja anonymisointi: Terveystiedot (PHI) on tehtävä tunnistamattomiksi usean toimipisteen tutkimuksia varten.
• Mittakaava ja suorituskyky: Miljoonat kuvat vaativat tehokasta käsittelyä ja tallennusta.
• Domain shift / vinouma: Hallitsevat toimittajat/protokollat voivat vääristää tekoälymalleja.
• Sääntely- ja vaatimustenmukaisuuskysymykset: Usean alueen käyttöönotot voivat liittyä HIPAA-, GDPR- tai paikallisiin säännöksiin.
DICOM-metadata on kuvantamisanalytiikan piilotettu tukiranka. PostDICOMin kaltaiset alustat havainnollistavat, kuinka hajanainen DICOM-tiedostoarkisto muutetaan haettavissa olevaksi, skaalautuvaksi ja metatieto-ohjatuksi ekosysteemiksi. Jos haluat tutustua PostDICOMiin, suosittelemme aloittamaan 7 päivän ilmaisen kokeilujakson.
|
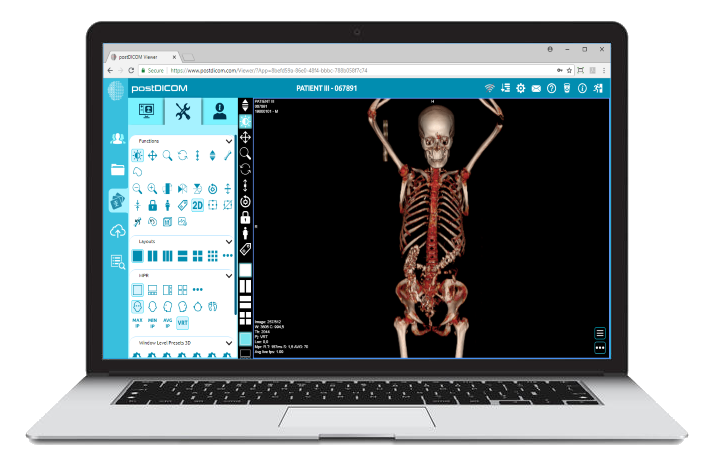
Cloud PACS ja Online DICOM-katseluohjelmaLataa DICOM-kuvat ja kliiniset asiakirjat PostDICOM-palvelimille. Tallenna, katsele, tee yhteistyötä ja jaa lääketieteellisiä kuvatiedostojasi. |